PitchPulse26 — A production World Cup prediction platform, end‑to‑end.
A full-stack World Cup prediction platform on serverless AWS with Terraform, Route 53 DNS, CloudWatch monitoring, and a documented rollback path.
Runtime overview
01
The Problem
Build a complete prediction platform that real users can sign up for, predict on, and trust to lock at kickoff — not a demo, not a toy. That meant owning every layer: a typed React frontend, a Node API with proper auth and validation, a relational schema that survives result updates, infrastructure as code, a real CI/CD pipeline, and the monitoring and rollback path required to operate it.
02
Product Experience
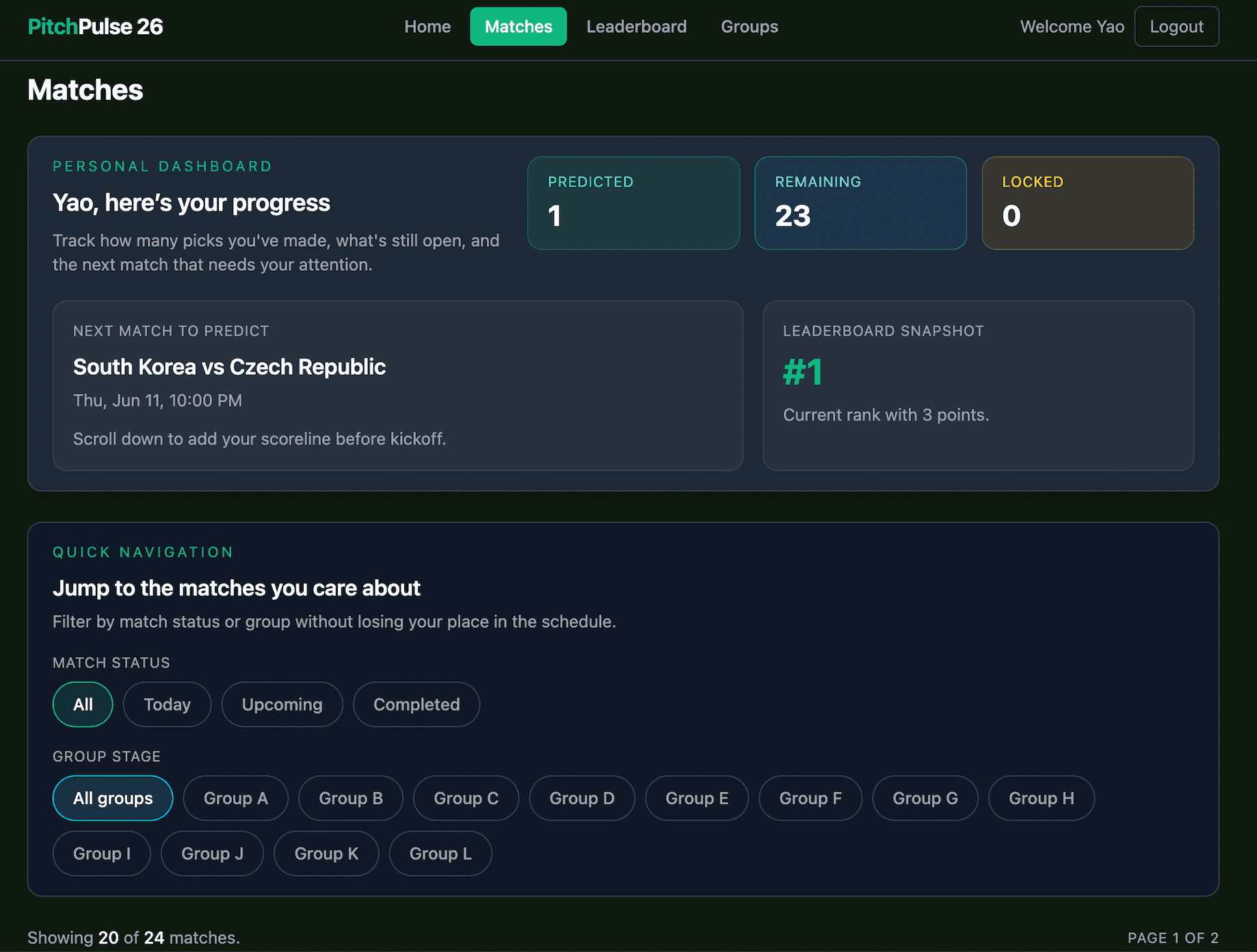
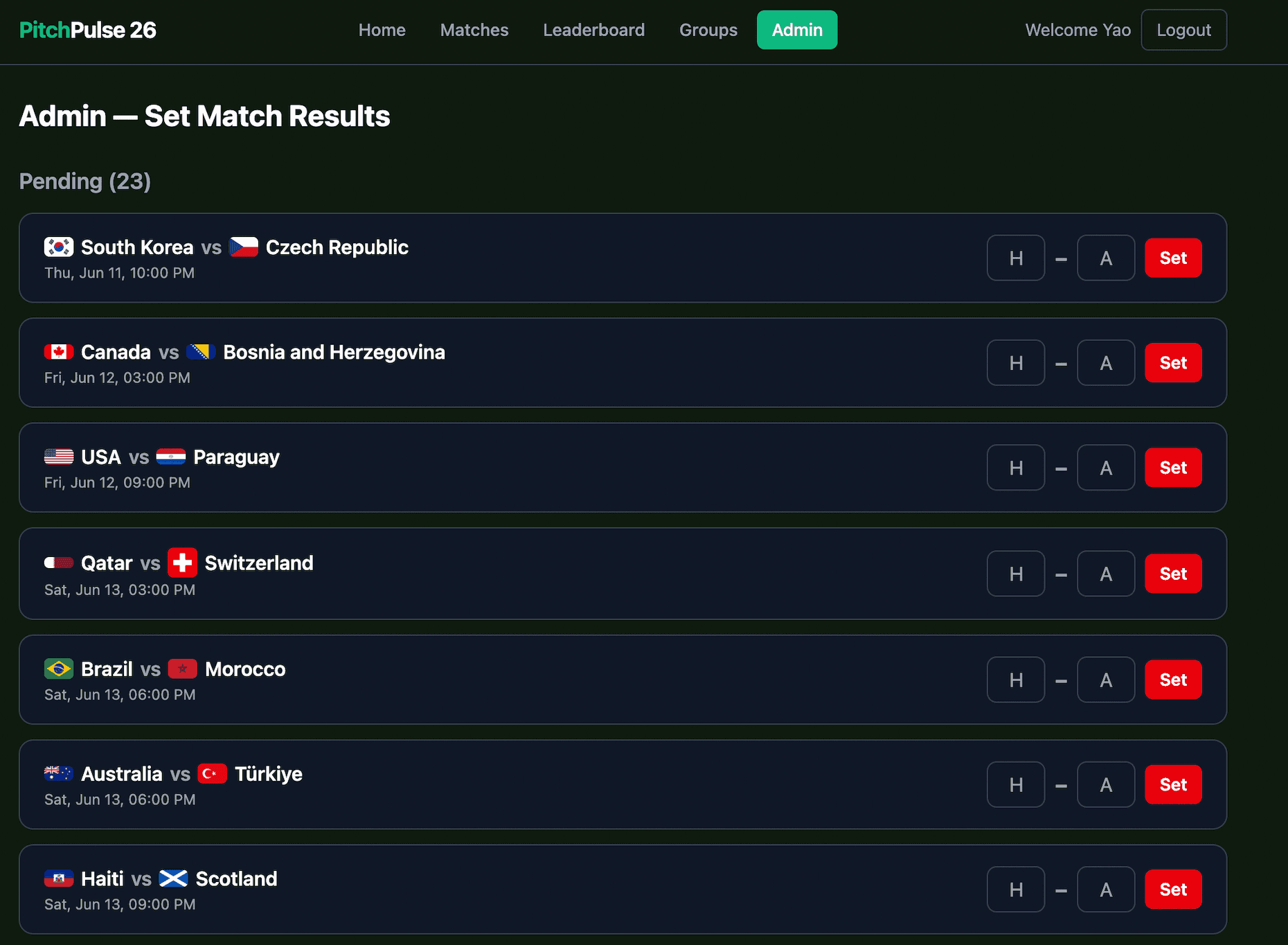
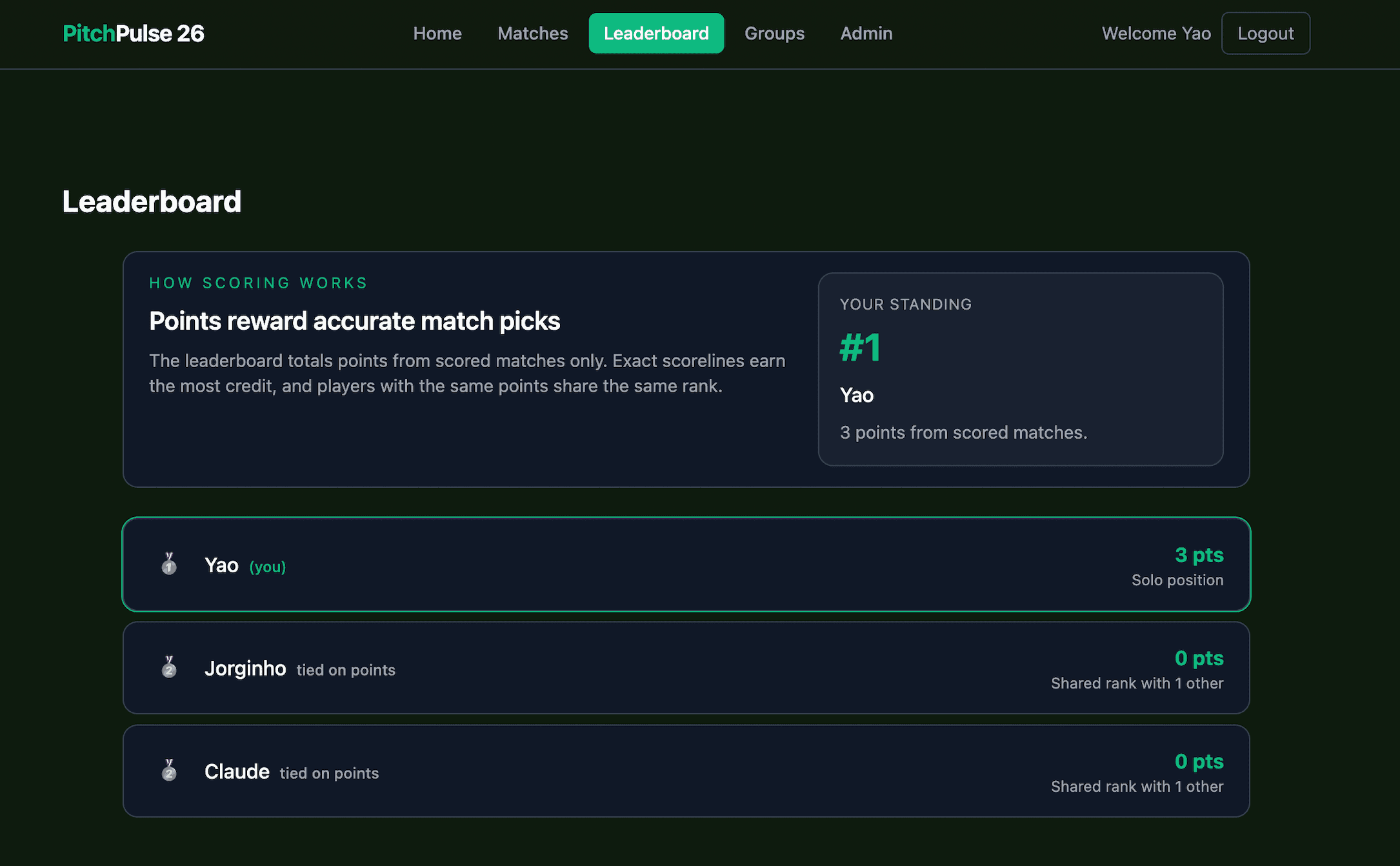
The strongest proof that this is a real product is that the core user flows are visible in the UI: making predictions, tracking personal progress, setting official results as an admin, and seeing scored outcomes reflected on the leaderboard.
Matches Workflow
Admin Result Entry
Leaderboard Feedback Loop
03
System Architecture
The runtime is fully serverless on AWS. The React + TypeScript client is delivered through AWS Amplify; the API is a Node + Express app fronted by API Gateway and executed on Lambda; data lives in a serverless PostgreSQL database on Neon, accessed via Prisma using the @prisma/adapter-neon driver over WebSocket so cold starts stay cheap.
High-level system architecture
Access
Frontend
API & Data
Configuration & Observability
Delivery & Recovery
Primary request path
User Browser → Route 53 → Amplify → React frontend → API Gateway → Lambda / Express → Prisma → Neon PostgreSQL
The custom domain was purchased through Namecheap, while DNS is managed in Route 53 through a hosted zone that points the public frontend domain to Amplify.
CloudWatch holds dashboards, alarms, and structured logs. SSM Parameter Store provides runtime configuration. GitHub Actions handles CI/CD, while Amplify deploys the frontend from the `main` branch and the backend deploy workflow packages and updates Lambda.
04
Tech Decisions & Tradeoffs
Lambda + API Gateway over ECS
Traffic is bursty around match windows and idle in between. Lambda costs nothing when nobody is predicting, scales instantly under bursts, and removes a class of capacity planning work I did not need at this scale. The tradeoff is cold-start latency, which the Neon WebSocket adapter and Express boot time keep within an acceptable budget.
Neon Postgres over RDS
I needed Postgres semantics (transactions, indexes, real joins) without paying for an idle RDS instance 24/7 or provisioning a proxy. Neon scales to zero, supports branching for migrations, and lets the same Prisma schema run unchanged in production.
Prisma + adapter-neon over node-postgres
Prisma gives me a typed schema and migration tooling. The Neon adapter speaks the WebSocket protocol Lambda needs to avoid TCP cold connect overhead. Together they keep the serverless story clean from data layer up.
Amplify over CloudFront + S3 directly
Amplify gives me CI integration, preview branches, and HTTPS without me wiring CloudFront, an OAC, and a deploy pipeline for a static SPA. The cost is some loss of fine-grained control, which I am happy to trade for time at this stage.
Backward-compatible Prisma migrations
Database rollbacks in production are dangerous. I avoid them by writing migrations that are forward-only and backward-compatible — the previous code version still runs against the new schema. Application rollback then becomes "redeploy the previous Lambda artifact," not "restore the database."
05
CI/CD Pipeline
GitHub Actions builds, tests, packages, and deploys on every push to main. The backend workflow runs tests, packages a Lambda artifact, uploads it to S3, updates Lambda, and verifies the deployment with a health check. Frontend delivery is handled through Amplify Git integration.
GitHub Actions pipeline
- git push
- Build + Test
- Lambda artifact → S3
- Terraform apply
- Deploy Lambda + Amplify
The Lambda artifact is uploaded to S3 with a versioned key so rollback is just a redeploy of the previous artifact — no rebuild required.
06
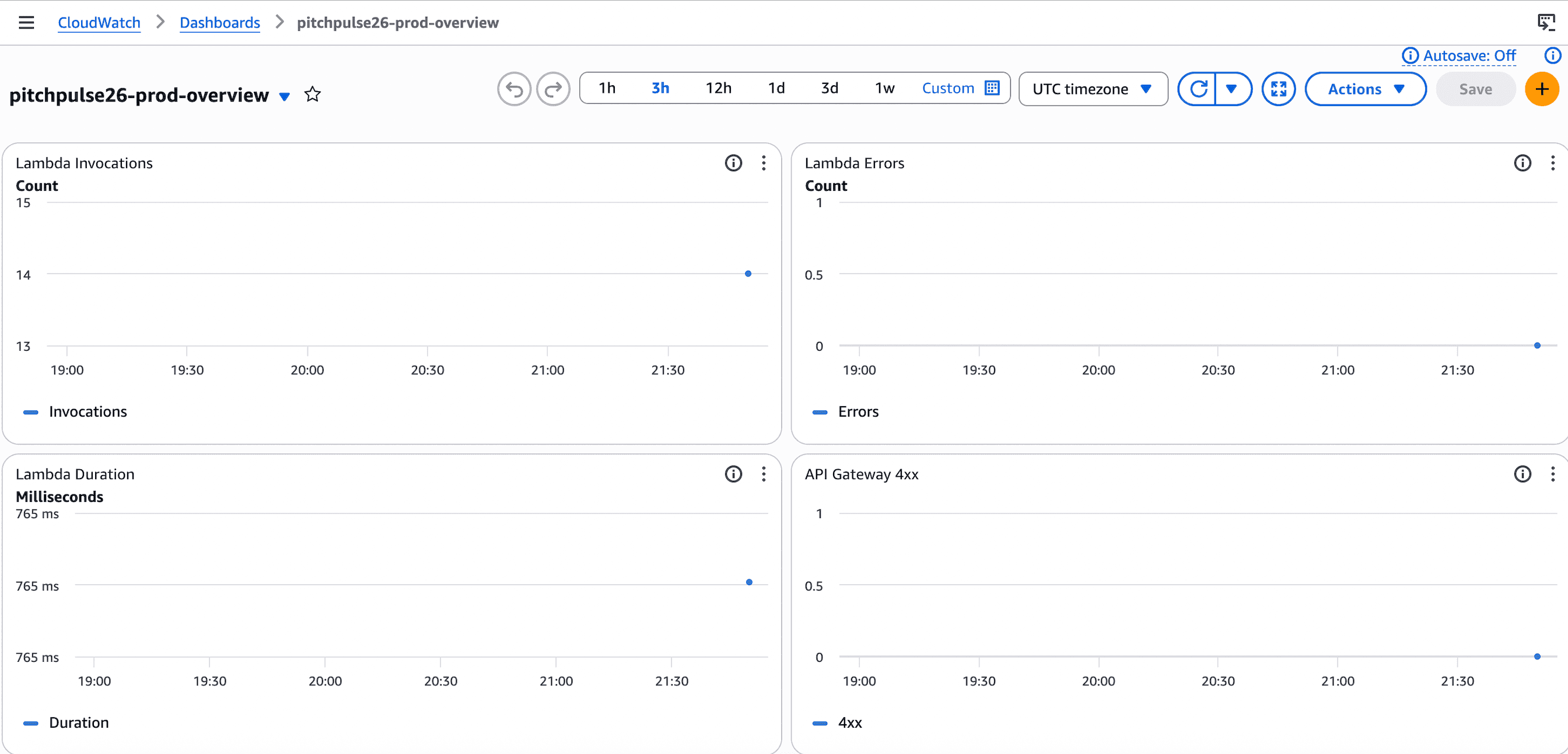
Reliability & Observability
CloudWatch is the source of truth in production. The dashboard and alarms are managed by Terraform under infra/monitoring.tf so the alerting story ships with the infrastructure, not after it.
Dashboard — pitchpulse26-prod-overview
- Lambda Invocations
- Lambda Errors
- Lambda Duration
- API Gateway 4xx
- API Gateway 5xx
- API Gateway Count
Alarms
pitchpulse26-lambda-errors— fires on any unhandled Lambda exceptions during a rolling window.pitchpulse26-api-5xx— fires on API Gateway 5xx responses, the user-visible failure mode.pitchpulse26-lambda-duration-high— catches latency regressions before users do.
Log Groups — 14 day retention
- /aws/lambda/pitchpulse26-api
- /aws/apigateway/pitchpulse26
Production Monitoring
07
Production Rollback
Production incidents need a known-good escape hatch. The rollback runbook lives in the repo at docs/runbooks/deployment-rollback.md and follows three rules:
- Frontend: roll back through Amplify deployment history, or revert the bad commit on
mainand let CI redeploy. - Backend: redeploy the last known-good Lambda artifact from S3. No rebuild.
- Database: avoid DB rollback entirely by keeping migrations backward-compatible. Code rollback alone is enough.
Alarms without runbooks generate noise, not action. This one is written before the alarm fires, not after.
08
Security Posture
- JWT authentication, 1-day expiry, secret loaded from environment.
- Passwords hashed with bcrypt (cost 10).
- Role-based access control:
userandadmin; admin endpoints gate result-setting. - Email verification gating — unverified users cannot submit predictions.
- Zod input validation on every endpoint; Helmet for HTTP security headers; CORS restricted to the configured origin.
- Rate limiting on auth endpoints (20 requests / 15 minutes) and a 10kb request body cap to blunt abuse.
- Prediction lockout enforced at API and UI layers after kickoff.
09
Outcomes & Operating Targets
The goal is not to claim production scale that does not exist; the goal is to operate against explicit targets I would defend in a review.
- Lambda error rate
- < 1%
- API 5xx rate
- < 0.5%
- Time to rollback
- < 5 min
- Log retention
- 14 days
- Cold-start budget
- < 1.5s p95
- Predictions / match
- 1 per user
alarm trips above this
user-visible failures
via S3-archived Lambda artifact
cost / compliance lever
Neon WS adapter assumed
enforced by unique constraint
10
What I'd Do Next
- Add canary deploys via Lambda alias weighting (10% → 100%) so deploys are revertible without a redeploy.
- Refactor the Matches page to reduce orchestration complexity and split critical data loads from secondary UI context.
- Move to RDS Proxy or pgBouncer if concurrent prediction load starts to saturate Neon connections during a kickoff window.
- Add Sentry on the client to catch frontend errors I currently do not see in CloudWatch.
- Author a k6 load test that hits
/api/matchesand/api/predictionsunder realistic match-window load and capture p95 latency alongside cold-start rate.
Want the full source?
Frontend, server, Terraform, and runbooks all live in one repo.